ソフトウェアの特許の事なら河野特許事務所 |
 閉じる 閉じる
|
||
| 一覧 | トップ | |||
AI関連発明の特許出願の勧め
~ 学習用データの工夫で特許を ~
2019.12.2 野口 富弘
近年、深層学習と呼ばれる、大量のデータを用いる機械学習関連の技術がめざましく進展しています。機械学習は、学習用データをコンピュータに入力し、学習用プログラムを使って学習モデルを生成するという手順で行われます。ここで、どのようなデータを与えて学習モデルを生成するかは、特許として権利化可能です。
以下では、検索クエリの意味を適切に解釈できる学習モデルを生成する情報処理装置の発明(特許第6584613号)について簡単に説明します。
1.本発明の概要
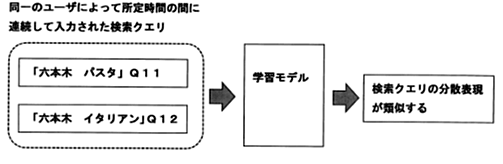
本発明は、ユーザが検索を行う際、一回の検索よりも、異なる検索クエリを用いて複数回検索する方が、意図する情報に到達する場合が多いとの観点から、同一のユーザによって所定時間の間に連続して入力された検索クエリ(例えば、図に示す検索クエリQ11「六本木 パスタ」、Q12「六本木 イタリアン」)は、類似する特徴を有するものとして、検索クエリの分散表現(ベクトル)が類似するように学習モデルを学習させることで、検索クエリが入力されると検索クエリの分散表現を出力する学習モデルを生成するものです
2.学習用データに対する工夫
(1)審査段階では、ユーザによるセッション内の時系列の連続したクエリから用語列を作成し、作成した用語列に含まれる用語の単語ベクトルが近接するように学習することが記載された引例が挙げられ、特許出願は進歩性がないとして一旦拒絶されました。
(2)しかし、出願人の以下の主張により、拒絶理由は解消されました。
すなわち、『本発明は、各用語の単語ベクトルが近接するように学習モデルを学習させるのではなく、引例と比較すると、ユーザによって区切られた検索クエリの区切りを考慮して、「六本木 パスタ」というクエリの分散表現と「六本木 イタリアン」というクエリの分散表現とが互いに類似するように学習モデルを学習させるという相違点があり、この相違点により、本発明は、各検索クエリの区切りに関する情報が消失することなく学習モデルを学習させることができ、ユーザによる検索行動の意図の類似性を精度よく判定できる学習モデルを生成できる。』
(3)このように、学習用データ(教師データ)の学習モデルへの与え方や学習用データの選択等に工夫をした場合、その工夫は特許になる可能性があります。
◆AI特許出願に関するご相談は、お気軽に河野特許事務所までご連絡ください。